注:本文档仅为石家庄铁道大学学生使用。
Only for STDU Students.
源代码地址:https://github.com/nnzhan/Graph-WaveNet
一、确定运行环境
从代码中的requirements.txt可以看到:
matplotlib
numpy
scipy
pandas
torch
argparse可以直接使用pytorch环境,与STSGCN环境相同,不需要重新准备镜像
二、按要求放置代码所需的数据集文件并上传服务器
1.下载DRCNN数据集文件至本地
谷歌云盘:https://drive.google.com/open?id=10FOTa6HXPqX8Pf5WRoRwcFnW9BrNZEIX
百度云盘:不知道为啥没办法放链接,自己改一下链接吧
https://pan.ba删除idu.com/s/14Yy9isAIZYdU__OYE删除QGa_g
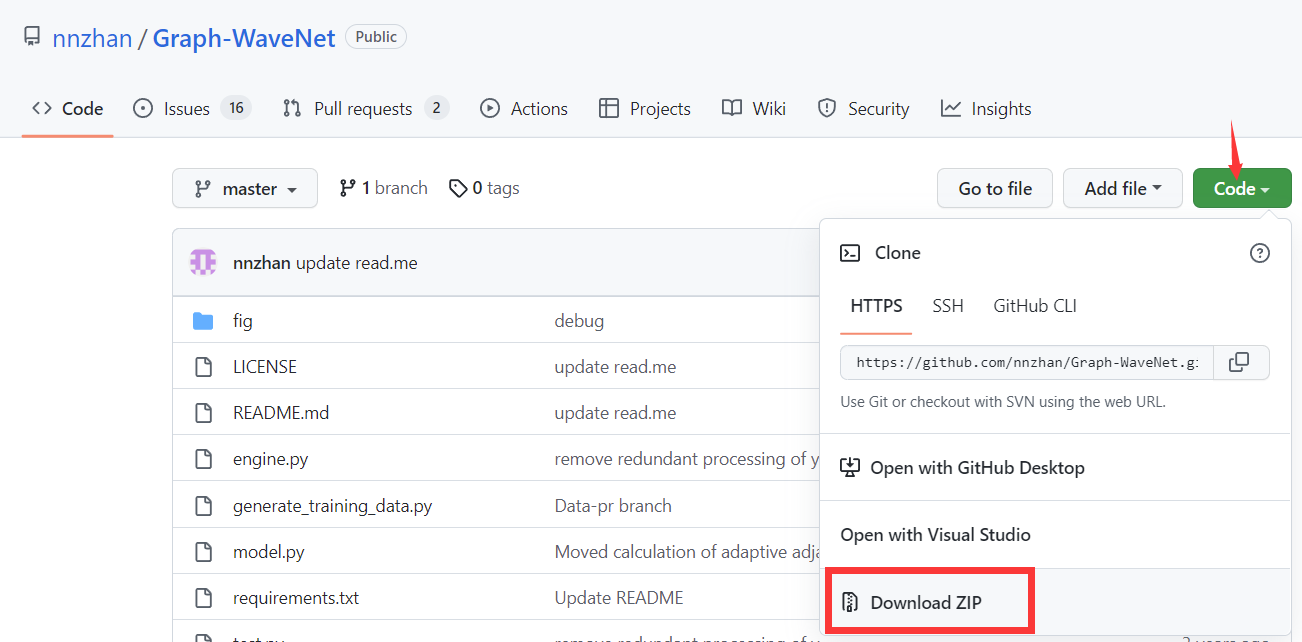
2.下载代码文件(github)
在github页面点击code-download ZIP
3.在自己的电脑解压代码和数据集文件,按要求放置数据集文件
1.在代码根目录创建data目录
2.在data目录下创建METR-LA,PEMS-BAY目录
3.将metr-la.h5,pems-bay.h5放在data目录下
目录结构如下
C:.
│ engine.py
│ generate_training_data.py
│ LICENSE
│ model.py
│ README.md
│ requirements.txt
│ test.py
│ train.py
│ util.py
│
├─data
│ │ metr-la.h5
│ │ pems-bay.h5
│ │
│ ├─METR-LA
│ └─PEMS-BAY
└─fig
model.pdf
model.png其实还要放一些文件,但是作者没说,通过报错可以看出来,后面有讲!!
4.将放入data后的文件夹重新打包,上传服务器
5.在服务器解压,再次注意解压后不要有多层文件夹!!
三、在HPC安装镜像并安装所需Python包
1.在自己创建的用于存放镜像的文件夹执行镜像编译命令(若已有镜像无需进行此步骤):
singularity pull docker://floydhub/pytorch:1.4.0-gpu.cuda10cudnn7-py3.54
2.进入镜像
singularity shell pytorch_1.4.0-gpu.cuda10cudnn7-py3.54.sif
3.查看所需Python包是否安装完全
pip list
4.安装缺少的Python包
若xxx为包名,则
pip install xxx
若速度过慢,可更换国内镜像源
pip install xxx -i https://pypi.tuna.tsinghua.edu.cn/simple/
若提示权限不足等问题,使用--user命令
pip install --user xxx -i https://pypi.tuna.tsinghua.edu.cn/simple/
四、生成数据集
1.进入镜像环境
2.切换至Graph wavenet代码根目录
我的目录命名为GWN,位于owoling/GWN
cd owoling/GWN
3.利用命令生成数据
# METR-LA
python generate_training_data.py --output_dir=data/METR-LA --traffic_df_filename=data/metr-la.h5
# PEMS-BAY
python generate_training_data.py --output_dir=data/PEMS-BAY --traffic_df_filename=data/pems-bay.h5在生成数据时可能有下方报错。原因是缺少tables包,安装即可
Traceback (most recent call last):
File "generate_training_data.py", line 109, in <module>
generate_train_val_test(args)
File "generate_training_data.py", line 54, in generate_train_val_test
df = pd.read_hdf(args.traffic_df_filename)
File "/usr/local/lib/python3.6/site-packages/pandas/io/pytables.py", line 384, in read_hdf
store = HDFStore(path_or_buf, mode=mode, **kwargs)
File "/usr/local/lib/python3.6/site-packages/pandas/io/pytables.py", line 484, in __init__
tables = import_optional_dependency("tables")
File "/usr/local/lib/python3.6/site-packages/pandas/compat/_optional.py", line 93, in import_optional_dependency
raise ImportError(message.format(name=name, extra=extra)) from None
ImportError: Missing optional dependency 'tables'. Use pip or conda to install tables. 安装命令:
pip install --user tables -i https://pypi.tuna.tsinghua.edu.cn/simple/
以下为运行生成数据命令时的输出:
Singularity pytorch_1.4.0-gpu.cuda10cudnn7-py3.54.sif:~/owoling/GWN> python generate_training_data.py --output_dir=data/METR
-LA --traffic_df_filename=data/metr-la.h5
data/METR-LA exists. Do you want to overwrite it? (y/n)y
x shape: (34249, 12, 207, 2) , y shape: (34249, 12, 207, 2)
train x: (23974, 12, 207, 2) y: (23974, 12, 207, 2)
val x: (3425, 12, 207, 2) y: (3425, 12, 207, 2)
test x: (6850, 12, 207, 2) y: (6850, 12, 207, 2)
Singularity pytorch_1.4.0-gpu.cuda10cudnn7-py3.54.sif:~/owoling/GWN> python generate_training_data.py --output_dir=data/PEMS
-BAY --traffic_df_filename=data/pems-bay.h5
data/PEMS-BAY exists. Do you want to overwrite it? (y/n)y
x shape: (52093, 12, 325, 2) , y shape: (52093, 12, 325, 2)
train x: (36465, 12, 325, 2) y: (36465, 12, 325, 2)
val x: (5209, 12, 325, 2) y: (5209, 12, 325, 2)
test x: (10419, 12, 325, 2) y: (10419, 12, 325, 2)
Singularity pytorch_1.4.0-gpu.cuda10cudnn7-py3.54.sif:~/owoling/GWN> 生成数据较慢,请耐心等待,直到回显Singularity pytorch_1.4.0-gpu.cuda10cudnn7-py3.54.sif:~/GWN>字样代表生成完成
五、在web控制台创建作业,尝试首次运行
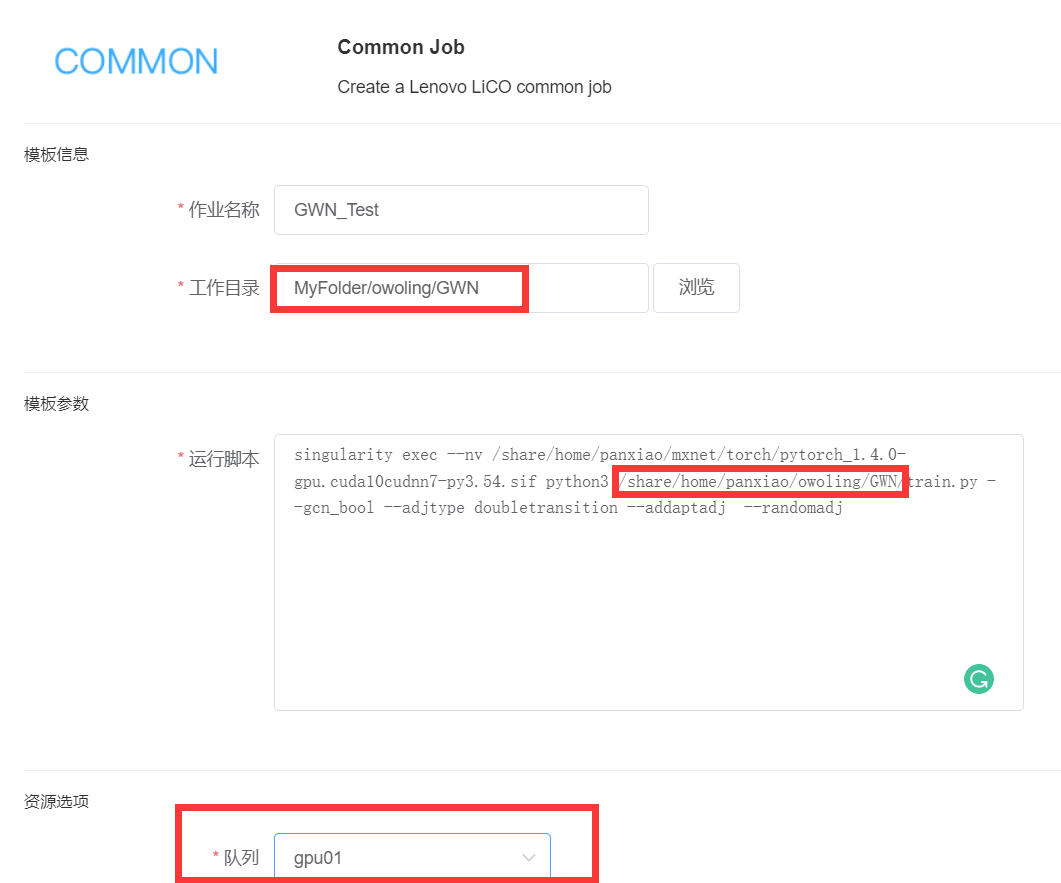
提交作业处选择Common Job
1.作业名称建议不要乱写,写自己运行项目相关的名字
2.工作目录是输出结果的目录,建议与代码路径保持一致
3.运行脚本,下方是我的。请灵性替换为你自己的目录路径,此外要注意python3
singularity exec --nv /share/home/panxiao/mxnet/torch/pytorch_1.4.0-gpu.cuda10cudnn7-py3.54.sif python3 /share/home/panxiao/owoling/GWN/train.py --gcn_bool --adjtype doubletransition --addaptadj --randomadj
4.队列选GPU01或GPU02
因为Graph WaveNet属于显卡学习类项目,因此需要选择可以调用显卡的队列
5.提交
六、检查报错并修改
1.补充DCRNN下的sensor_graph文件夹
第一次运行会有如下报错
Traceback (most recent call last):
File "/share/home/panxiao/owoling/GWN/train.py", line 173, in <module>
main()
File "/share/home/panxiao/owoling/GWN/train.py", line 43, in main
sensor_ids, sensor_id_to_ind, adj_mx = util.load_adj(args.adjdata,args.adjtype)
File "/share/home/panxiao/owoling/GWN/util.py", line 125, in load_adj
sensor_ids, sensor_id_to_ind, adj_mx = load_pickle(pkl_filename)
File "/share/home/panxiao/owoling/GWN/util.py", line 114, in load_pickle
with open(pickle_file, 'rb') as f:
FileNotFoundError: [Errno 2] No such file or directory: 'data/sensor_graph/adj_mx.pkl'可以在https://github.com/liyaguang/DCRNN找到data/sensor_graph文件夹,下载后上传到服务器对应的data文件夹下
2.更改默认显卡设置
第二次尝试运行有如下报错,原因是默认的--device参数为cuda:3
Traceback (most recent call last):
File "/share/home/panxiao/owoling/GWN/train.py", line 173, in <module>
main()
File "/share/home/panxiao/owoling/GWN/train.py", line 46, in main
supports = [torch.tensor(i).to(device) for i in adj_mx]
File "/share/home/panxiao/owoling/GWN/train.py", line 46, in <listcomp>
supports = [torch.tensor(i).to(device) for i in adj_mx]
RuntimeError: CUDA error: invalid device ordinal
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.将train.py第10行的cuda:3更改为cuda:0
让程序默认调用第一张显卡。不知道为啥这个程序默认调用第3张,难道他的电脑有好几张显卡???
3.在根目录下建立garage文件夹
程序在运行一个周期后,会出现下列报错,原因是根目录没有缓存文件夹garage
job start time is Mon Aug 8 15:29:19 CST 2022
gpu02
Namespace(addaptadj=True, adjdata='data/sensor_graph/adj_mx.pkl', adjtype='doubletransition', aptonly=False, batch_size=64, data='data/METR-LA', device='cuda:0', dropout=0.3, epochs=100, expid=1, gcn_bool=True, in_dim=2, learning_rate=0.001, nhid=32, num_nodes=207, print_every=50, randomadj=True, save='./garage/metr', seq_length=12, weight_decay=0.0001)
start training...
Iter: 000, Train Loss: 11.6966, Train MAPE: 0.2883, Train RMSE: 13.8833
Iter: 050, Train Loss: 4.1836, Train MAPE: 0.1065, Train RMSE: 8.3822
Iter: 100, Train Loss: 4.7161, Train MAPE: 0.1182, Train RMSE: 7.8100
Iter: 150, Train Loss: 4.0692, Train MAPE: 0.1216, Train RMSE: 7.8937
Iter: 200, Train Loss: 4.0786, Train MAPE: 0.1134, Train RMSE: 8.1442
Iter: 250, Train Loss: 3.7570, Train MAPE: 0.0907, Train RMSE: 7.6340
Iter: 300, Train Loss: 3.6783, Train MAPE: 0.1085, Train RMSE: 7.2867
Iter: 350, Train Loss: 3.4522, Train MAPE: 0.1002, Train RMSE: 6.6939
Epoch: 001, Inference Time: 6.7627 secs
Epoch: 001, Train Loss: 4.0712, Train MAPE: 0.1145, Train RMSE: 7.7452, Valid Loss: 3.3757, Valid MAPE: 0.0942, Valid RMSE: 6.3937, Training Time: 183.8179/epoch
Traceback (most recent call last):
File "/share/home/panxiao/owoling/GWN/train.py", line 173, in <module>
main()
File "/share/home/panxiao/owoling/GWN/train.py", line 124, in main
torch.save(engine.model.state_dict(), args.save+"_epoch_"+str(i)+"_"+str(round(mvalid_loss,2))+".pth")
File "/share/home/panxiao/.local/lib/python3.6/site-packages/torch/serialization.py", line 376, in save
with _open_file_like(f, 'wb') as opened_file:
File "/share/home/panxiao/.local/lib/python3.6/site-packages/torch/serialization.py", line 230, in _open_file_like
return _open_file(name_or_buffer, mode)
File "/share/home/panxiao/.local/lib/python3.6/site-packages/torch/serialization.py", line 211, in __init__
super(_open_file, self).__init__(open(name, mode))
FileNotFoundError: [Errno 2] No such file or directory: './garage/metr_epoch_1_3.38.pth'
job end time is Mon Aug 8 15:32:54 CST 2022在根目录建立空文件夹garage即可
本人一脸问号:为啥你不在文档一次性说清楚啊,非让我一次次试(╬◣д◢)
七、查看输出结果
在作业列表点击运行中的作业可以查看正在输出的结果,每一次epoch会有一次输出
完整运行完后可以在已完成查看完整输出
部分输出结果如下:
Epoch: 098, Inference Time: 6.7918 secs
Epoch: 098, Train Loss: 2.7425, Train MAPE: 0.0726, Train RMSE: 5.4403, Valid Loss: 2.7974, Valid MAPE: 0.0798, Valid RMSE: 5.4811, Training Time: 192.8321/epoch
Iter: 000, Train Loss: 2.8798, Train MAPE: 0.0793, Train RMSE: 5.8021
Iter: 050, Train Loss: 2.6702, Train MAPE: 0.0704, Train RMSE: 5.3364
Iter: 100, Train Loss: 2.8620, Train MAPE: 0.0747, Train RMSE: 5.7113
Iter: 150, Train Loss: 2.8121, Train MAPE: 0.0756, Train RMSE: 5.6285
Iter: 200, Train Loss: 2.6808, Train MAPE: 0.0694, Train RMSE: 5.2505
Iter: 250, Train Loss: 2.8685, Train MAPE: 0.0750, Train RMSE: 5.6448
Iter: 300, Train Loss: 2.7463, Train MAPE: 0.0767, Train RMSE: 5.5610
Iter: 350, Train Loss: 2.8933, Train MAPE: 0.0823, Train RMSE: 5.7709
Epoch: 099, Inference Time: 6.7306 secs
Epoch: 099, Train Loss: 2.7444, Train MAPE: 0.0726, Train RMSE: 5.4408, Valid Loss: 2.7720, Valid MAPE: 0.0760, Valid RMSE: 5.4096, Training Time: 193.2898/epoch
Iter: 000, Train Loss: 2.9209, Train MAPE: 0.0843, Train RMSE: 6.1575
Iter: 050, Train Loss: 2.7627, Train MAPE: 0.0703, Train RMSE: 5.4284
Iter: 100, Train Loss: 2.6433, Train MAPE: 0.0736, Train RMSE: 5.4950
Iter: 150, Train Loss: 2.7847, Train MAPE: 0.0766, Train RMSE: 5.6070
Iter: 200, Train Loss: 2.8240, Train MAPE: 0.0781, Train RMSE: 5.5502
Iter: 250, Train Loss: 2.8650, Train MAPE: 0.0817, Train RMSE: 5.9751
Iter: 300, Train Loss: 2.8060, Train MAPE: 0.0749, Train RMSE: 5.5174
Iter: 350, Train Loss: 2.8039, Train MAPE: 0.0830, Train RMSE: 5.5693
Epoch: 100, Inference Time: 6.7897 secs
Epoch: 100, Train Loss: 2.7450, Train MAPE: 0.0727, Train RMSE: 5.4468, Valid Loss: 2.7905, Valid MAPE: 0.0753, Valid RMSE: 5.4157, Training Time: 193.2305/epoch
Average Training Time: 193.6062 secs/epoch
Average Inference Time: 6.7898 secs
Training finished
The valid loss on best model is 2.7415
Evaluate best model on test data for horizon 1, Test MAE: 2.2462, Test MAPE: 0.0530, Test RMSE: 3.8577
Evaluate best model on test data for horizon 2, Test MAE: 2.5176, Test MAPE: 0.0619, Test RMSE: 4.6330
Evaluate best model on test data for horizon 3, Test MAE: 2.7014, Test MAPE: 0.0686, Test RMSE: 5.1452
Evaluate best model on test data for horizon 4, Test MAE: 2.8549, Test MAPE: 0.0743, Test RMSE: 5.5602
Evaluate best model on test data for horizon 5, Test MAE: 2.9760, Test MAPE: 0.0788, Test RMSE: 5.8914
Evaluate best model on test data for horizon 6, Test MAE: 3.0824, Test MAPE: 0.0827, Test RMSE: 6.1838
Evaluate best model on test data for horizon 7, Test MAE: 3.1826, Test MAPE: 0.0860, Test RMSE: 6.4367
Evaluate best model on test data for horizon 8, Test MAE: 3.2706, Test MAPE: 0.0890, Test RMSE: 6.6596
Evaluate best model on test data for horizon 9, Test MAE: 3.3447, Test MAPE: 0.0915, Test RMSE: 6.8512
Evaluate best model on test data for horizon 10, Test MAE: 3.4156, Test MAPE: 0.0940, Test RMSE: 7.0282
Evaluate best model on test data for horizon 11, Test MAE: 3.4823, Test MAPE: 0.0963, Test RMSE: 7.1851
Evaluate best model on test data for horizon 12, Test MAE: 3.5503, Test MAPE: 0.0984, Test RMSE: 7.3310
On average over 12 horizons, Test MAE: 3.0520, Test MAPE: 0.0812, Test RMSE: 6.0636
Total time spent: 20083.0301
job end time is Fri Jul 22 03:01:27 CST 2022八、部分报错及解决方法
1.显存不足
报错如下:
job start time is Mon Aug 8 15:27:07 CST 2022
c25
Namespace(addaptadj=True, adjdata='data/sensor_graph/adj_mx.pkl', adjtype='doubletransition', aptonly=False, batch_size=64, data='data/METR-LA', device='cuda:0', dropout=0.3, epochs=100, expid=1, gcn_bool=True, in_dim=2, learning_rate=0.001, nhid=32, num_nodes=207, print_every=50, randomadj=True, save='./garage/metr', seq_length=12, weight_decay=0.0001)
start training...
Traceback (most recent call last):
File "/share/home/panxiao/owoling/GWN/train.py", line 173, in <module>
main()
File "/share/home/panxiao/owoling/GWN/train.py", line 84, in main
metrics = engine.train(trainx, trainy[:,0,:,:])
File "/share/home/panxiao/owoling/GWN/engine.py", line 24, in train
loss.backward()
File "/share/home/panxiao/.local/lib/python3.6/site-packages/torch/_tensor.py", line 307, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph, inputs=inputs)
File "/share/home/panxiao/.local/lib/python3.6/site-packages/torch/autograd/__init__.py", line 156, in backward
allow_unreachable=True, accumulate_grad=True) # allow_unreachable flag
RuntimeError: CUDA out of memory. Tried to allocate 52.00 MiB (GPU 0; 31.75 GiB total capacity; 1.18 GiB already allocated; 54.50 MiB free; 1.33 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
job end time is Mon Aug 8 15:27:31 CST 2022乱七八糟的不用看,重点看这句
RuntimeError: CUDA out of memory.
出现这句话代表集群的显存已满,只能等待管理员释放资源或其他人运行完成。
我暂时只遇到过这一个问题,如有其它问题欢迎前来询问!


深受启发,谢谢uu,但是运行过程中出现了 Expected 2D (unbatched) or 3D (batched) input to conv1d, but got input of size: [64, 32, 207, 13]报错。想问下您遇到过嘛?
@菜菜求带飞 解决了吗,请问一下
@菜菜求带飞 请问解决了吗?
@菜菜求带飞 将里面的1d改为2d就行啦 ,就可以运行啦。。。
@求带。。 请问大佬在哪改呀
@菜菜求带飞 同样的错误 。。。
@菜菜求带飞 你是STDU的学生吗?
@菜菜求带飞 没遇到过,看报错像是输入一维卷积的维度有问题。
感谢分享,赞一个